RL Weekly 36: AlphaZero with a Learned Model achieves SotA in Atari
Por um escritor misterioso
Descrição
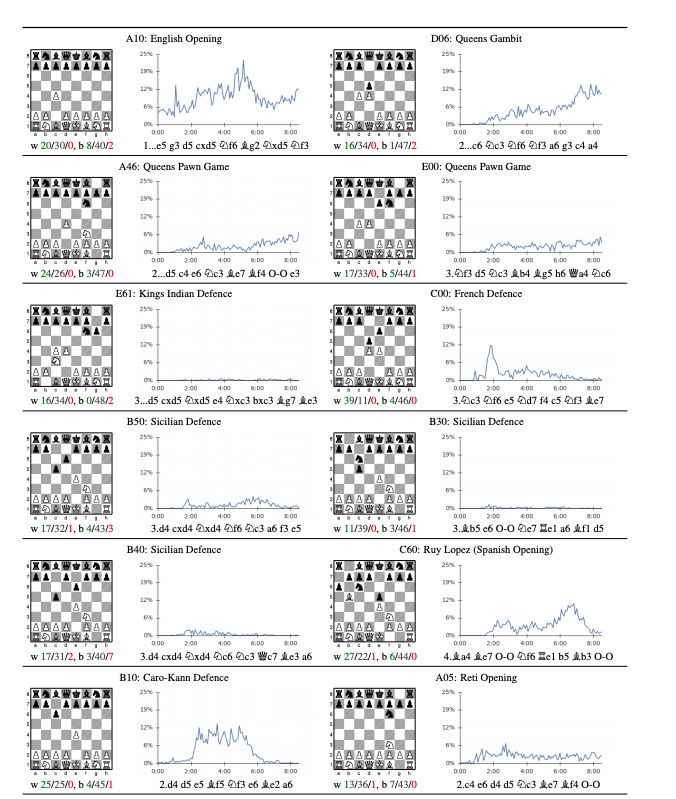
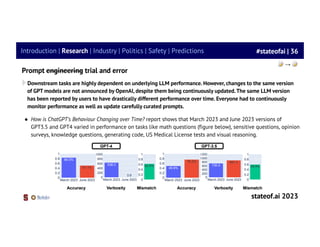
In this issue, we look at MuZero, DeepMind’s new algorithm that learns a model and achieves AlphaZero performance in Chess, Shogi, and Go and achieves state-of-the-art performance on Atari. We also look at Safety Gym, OpenAI’s new environment suite for safe RL.
Kristian Kersting
Kristian Kersting
Summaries from arXiv e-Print archive on
State of AI Report 2023 - Air Street Capital

Home

Superhuman Performance on the Atari 100K Benchmark: The Power of BBF - A New Value-Based RL Agent from Google DeepMind, Mila, and Universite de Montreal - MarkTechPost

deep learning – Severely Theoretical
Johan Gras (@gras_johan) / X

PDF) A Review for Deep Reinforcement Learning in Atari:Benchmarks, Challenges, and Solutions
de
por adulto (o preço varia de acordo com o tamanho do grupo)