What can and can't language models do? Lessons learned from BIGBench
Por um escritor misterioso
Descrição
So what exactly can and can’t language models do? What's the least impressive thing GPT-4 won't be able to do? What will GPT-4 be incapable of?
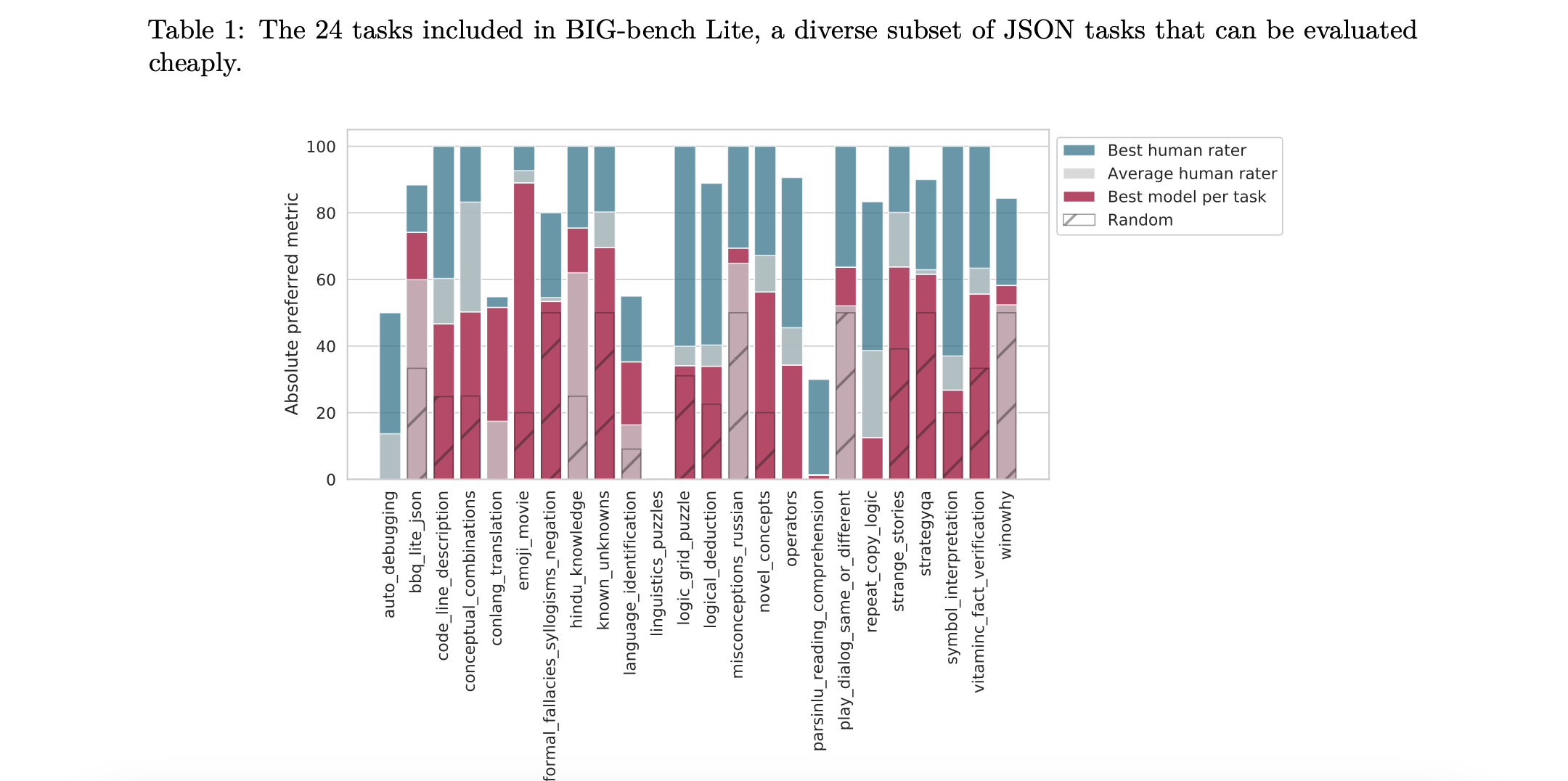
BIGBench is kind of a way to figure this out. BigBench, aka “The Beyond the Imitation Game” Benchmark, is an attempt to explore the capabilities of large language models over a wide variety of tasks. All the tasks are enumerated here.
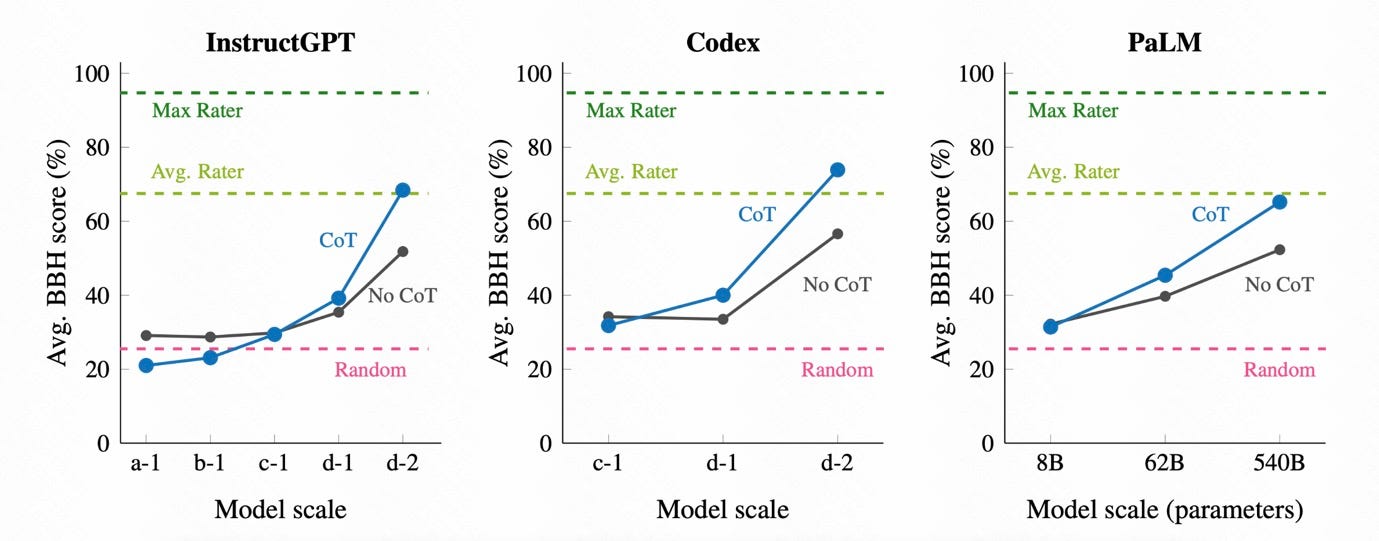
I looked through every BIGBench task and took the ones that compared both GPT3 and PaLM against humans.
* Spreadsheet

Using cognitive psychology to understand GPT-3

New Benchmarks Test the Limits of Large Language Models
Benchmark of LLMs (Part 1): Glue & SuperGLUE, Adversarial NLI, Big

Dual Process Theory for Large Language Models: An overview of

Large Language Models In A Nutshell - FourWeekMBA
GitHub - uncbiag/Awesome-Foundation-Models: A curated list of
BIG-Bench: The New Benchmark for Language Models
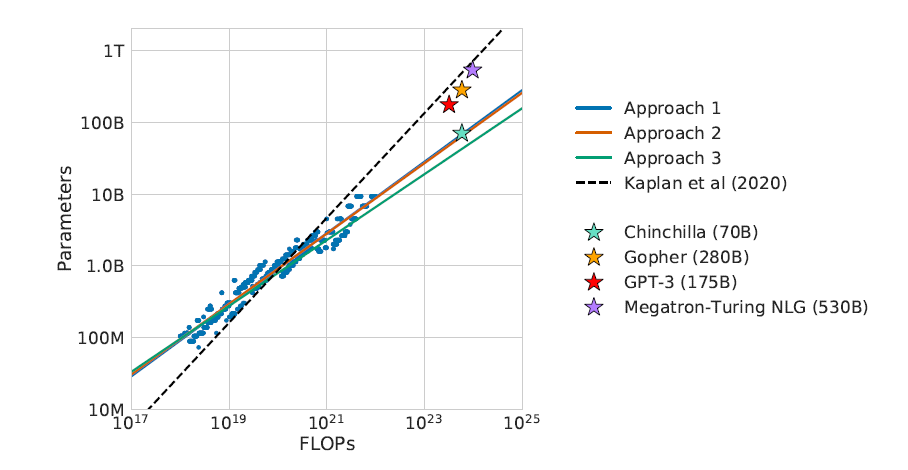
A New AI Trend: Chinchilla (70B) Greatly Outperforms GPT-3 (175B
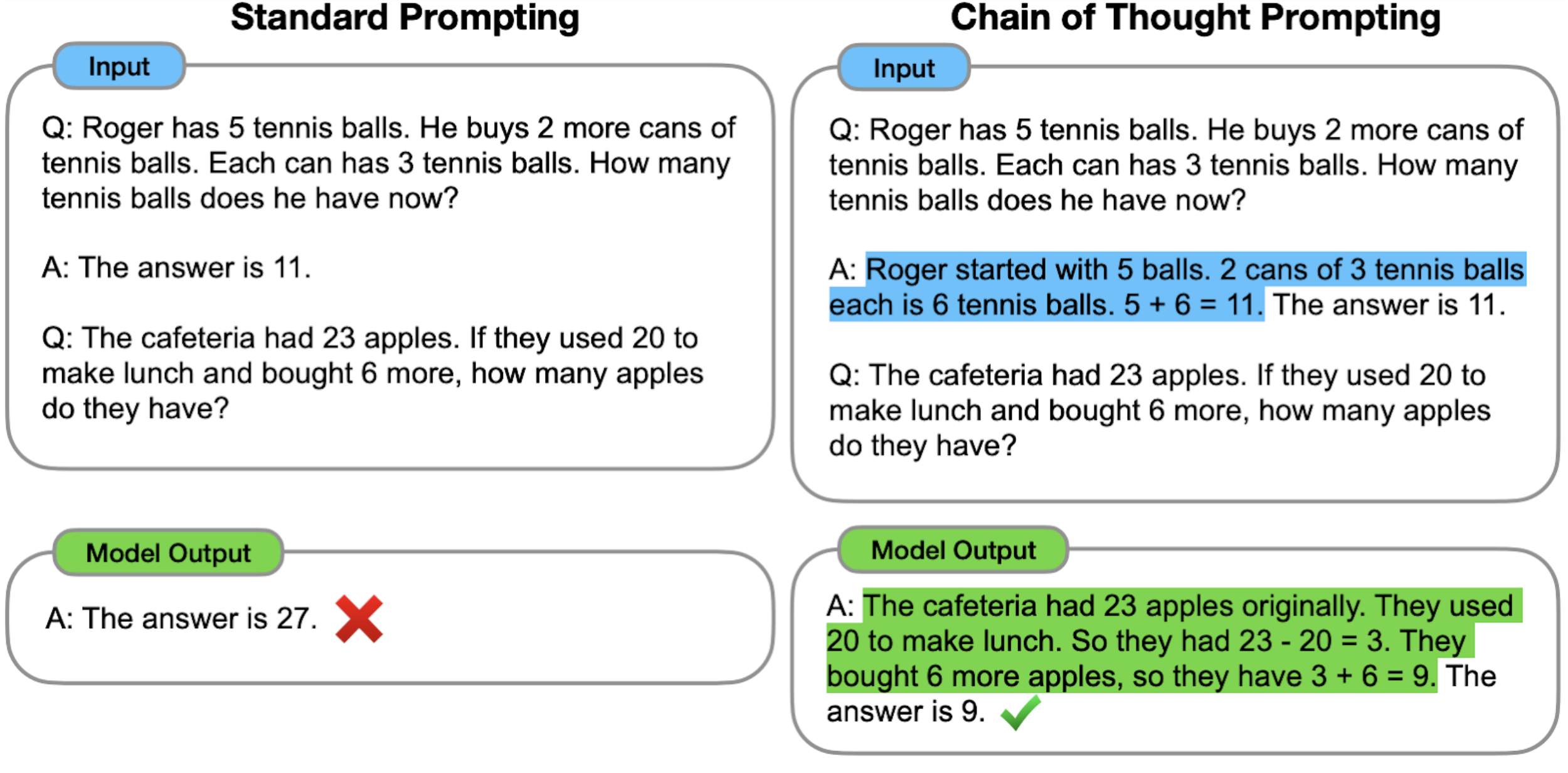
Language Models Perform Reasoning via Chain of Thought – Google

PDF) Challenges and Applications of Large Language Models
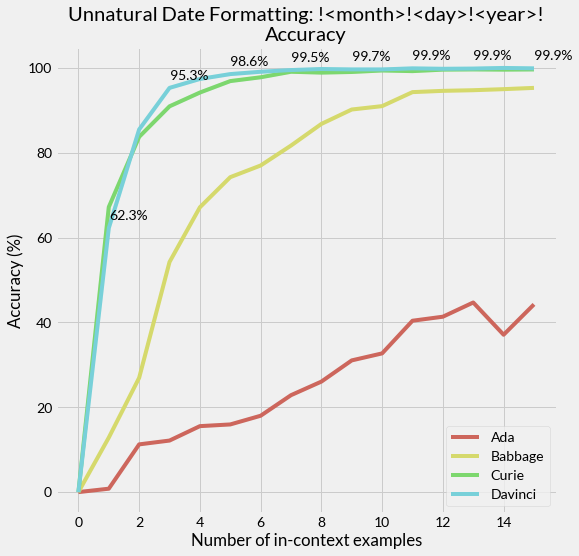
Extrapolating to Unnatural Language Processing with GPT-3's In
de
por adulto (o preço varia de acordo com o tamanho do grupo)