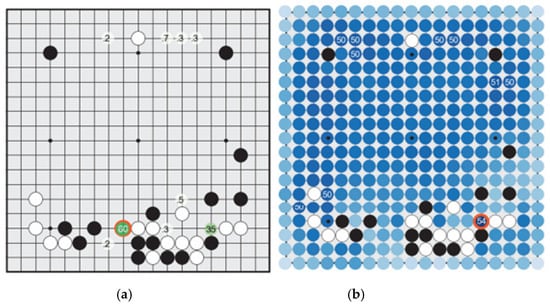
Empirical evaluation of AlphaGo Zero. a Performance of self-play
Por um escritor misterioso
Descrição
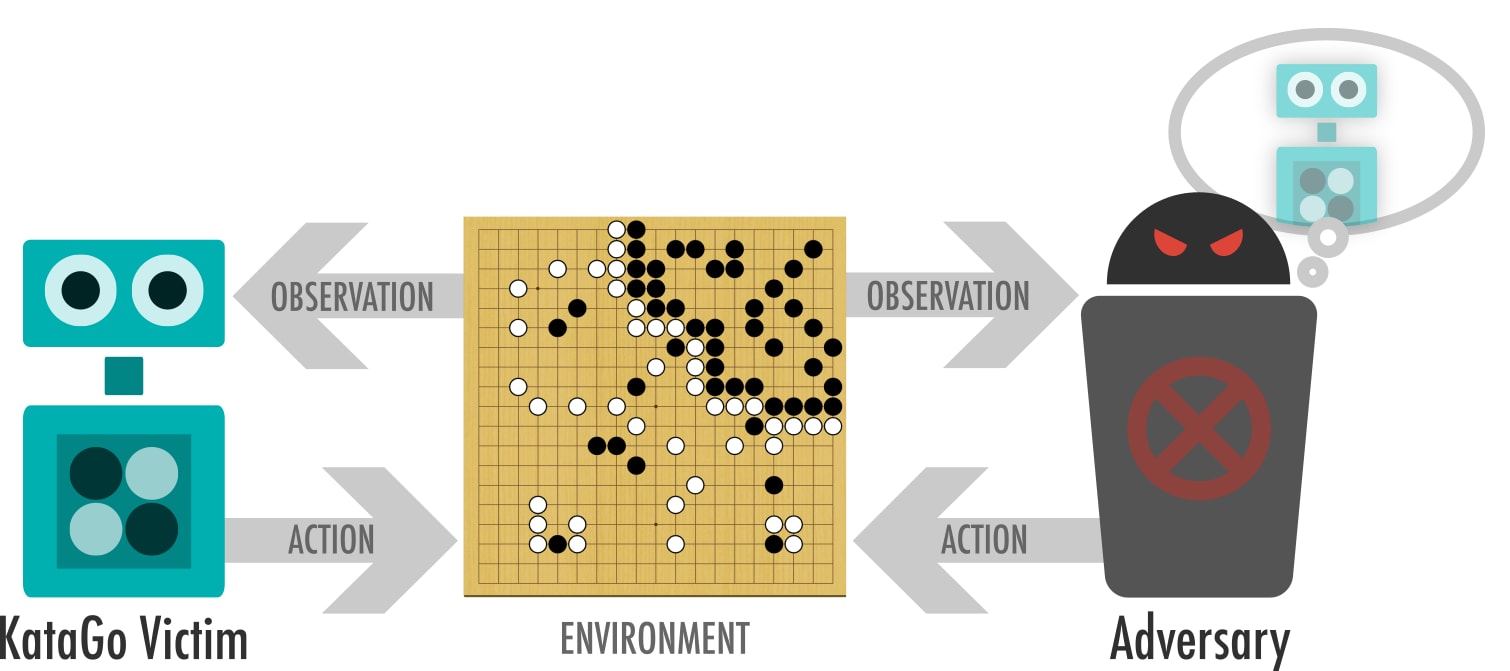
Even Superhuman Go AIs Have Surprising Failure Modes — LessWrong

neural network - AlphaGo Zero board evaluation function uses multiple time steps as an input Why? - Stack Overflow
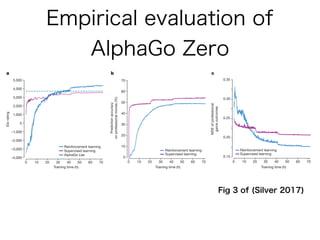
AlphaGo and AlphaGo Zero
A (Long) Peek into Reinforcement Learning

Extracting tactics learned from self-play in general games - ScienceDirect

PDF] Accelerating Self-Play Learning in Go
Philosophies, Free Full-Text

Empirical Analysis of PUCT Algorithm with Evaluation Functions of Different Quality

Systematic Performance Evaluation of Reinforcement Learning Algorithms Applied to Wastewater Treatment Control Optimization
de
por adulto (o preço varia de acordo com o tamanho do grupo)