wiki-reading/data/answer.vocab at master · google-research-datasets/wiki-reading · GitHub
Por um escritor misterioso
Descrição
This repository contains the three WikiReading datasets as used and described in WikiReading: A Novel Large-scale Language Understanding Task over Wikipedia, Hewlett, et al, ACL 2016 (the English WikiReading dataset) and Byte-level Machine Reading across Morphologically Varied Languages, Kenter et al, AAAI-18 (the Turkish and Russian datasets). - wiki-reading/data/answer.vocab at master · google-research-datasets/wiki-reading
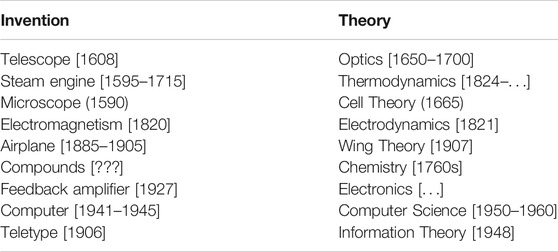
Frontiers The Future of Computational Linguistics: On Beyond Alchemy
GitHub - google-research-datasets/WikipediaAbbreviationData: This data set consists of 24,000 English sentences, extracted from Wikipedia in 2017, annotated to support development of an abbreviation expansion system for text-to-speech synthesis (e.g.
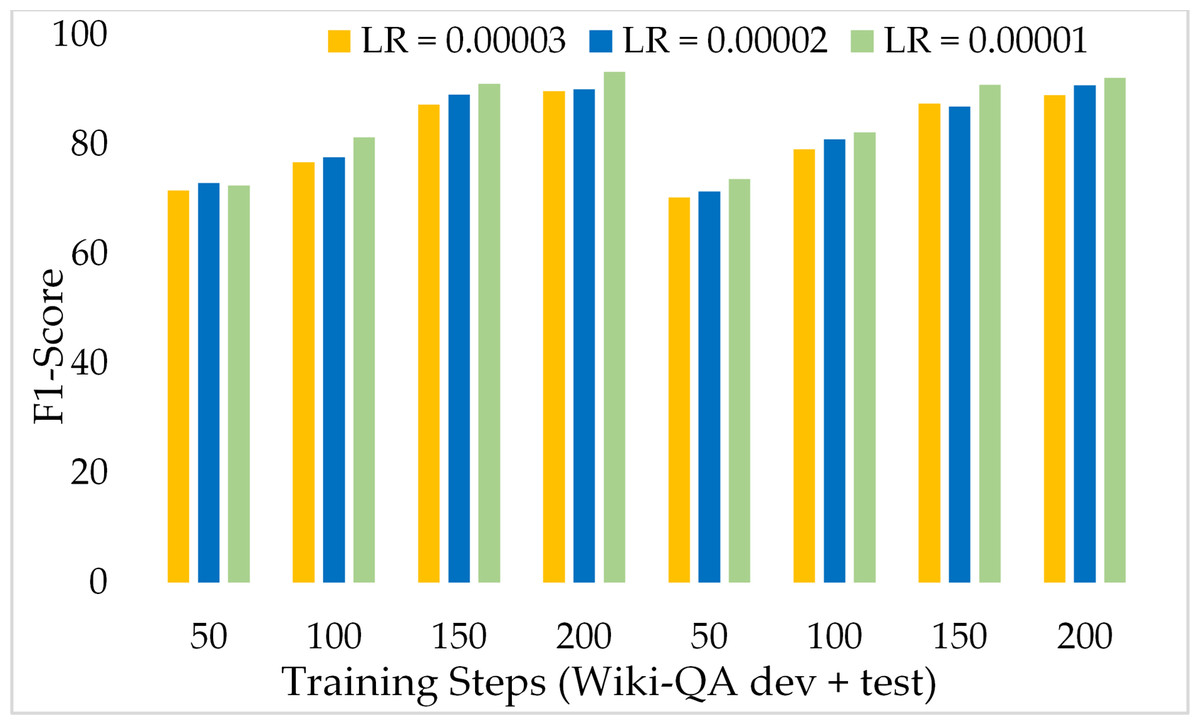
On solving textual ambiguities and semantic vagueness in MRC based question answering using generative pre-trained transformers [PeerJ]
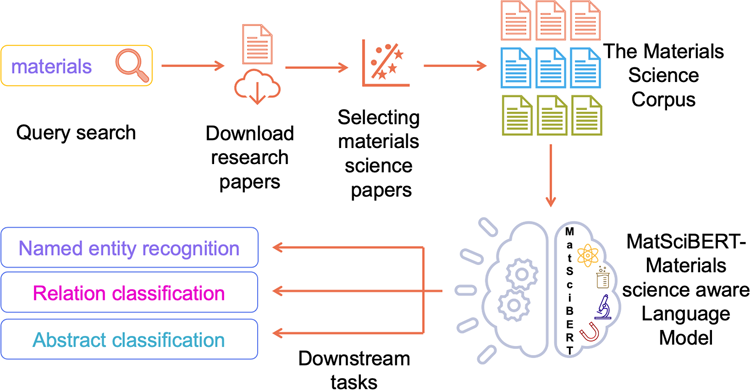
MatSciBERT: A materials domain language model for text mining and information extraction
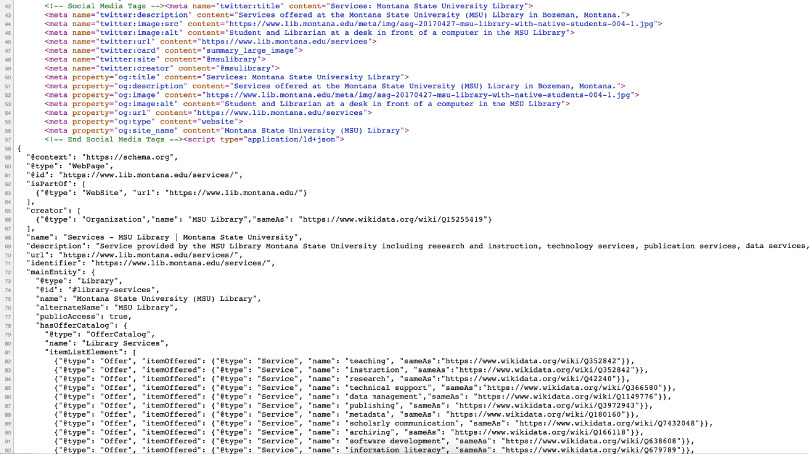
Wikidata and knowledge graphs in practice: Using semantic SEO to create discoverable, accessible, machine-readable definitions of the people, places, and services in Libraries and Archives - IOS Press
Data Catalog Vocabulary (DCAT) - Version 2

Open Source: Most Up-to-Date Encyclopedia, News & Reviews
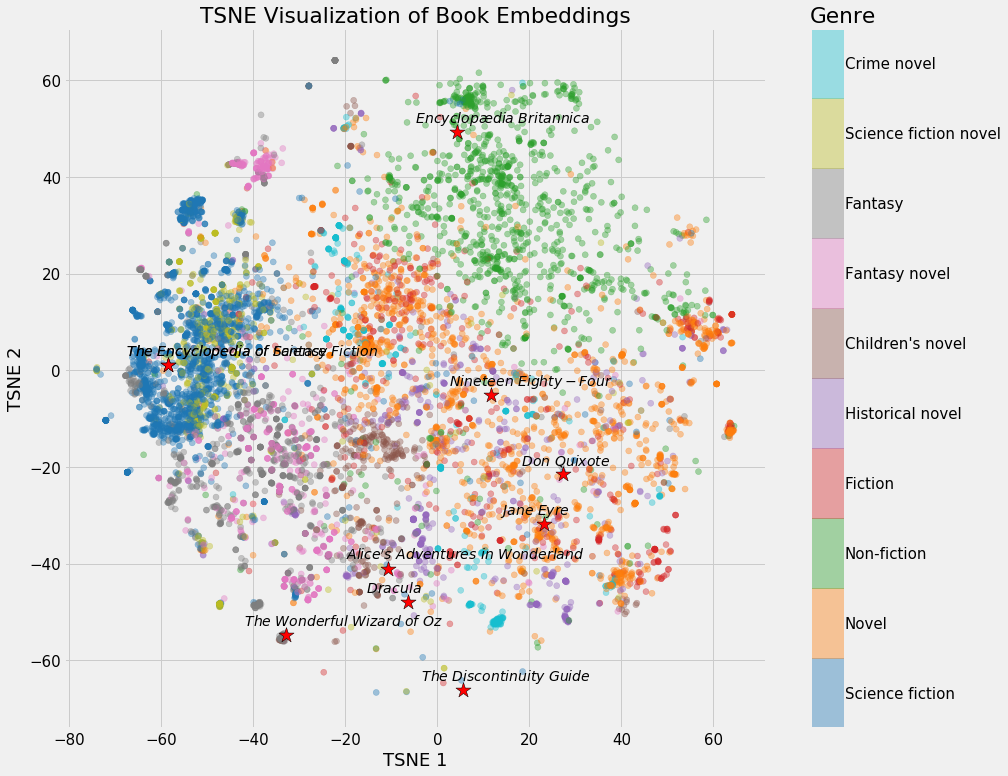
Neural Network Embeddings Explained, by Will Koehrsen

Applied Sciences, Free Full-Text

PDF) Mind the (Language) Gap: Generation of Multilingual Wikipedia Summaries from Wikidata for ArticlePlaceholders
de
por adulto (o preço varia de acordo com o tamanho do grupo)






