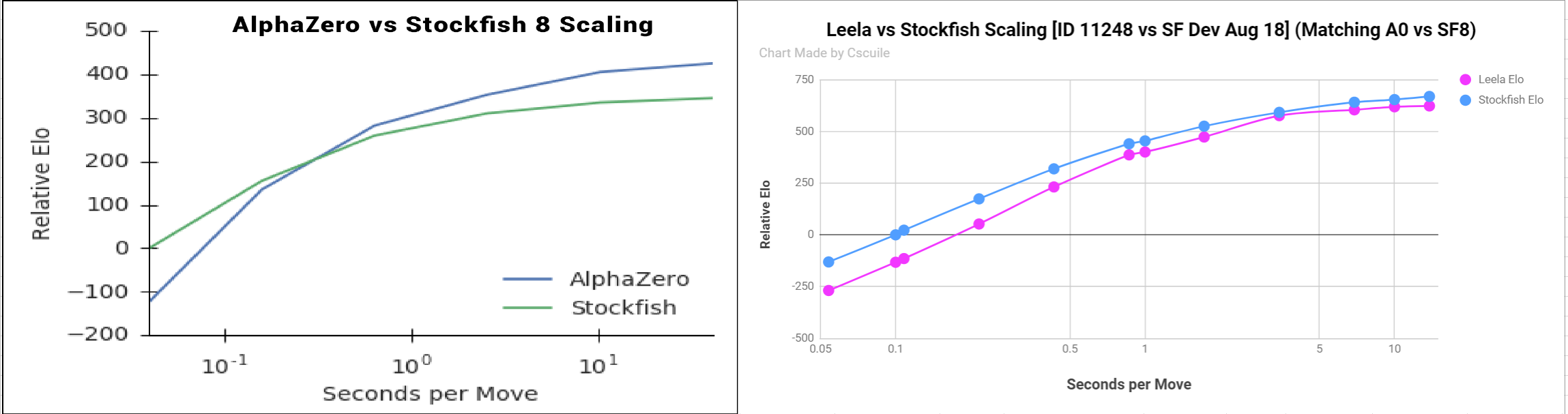
From Zero to Master in Hours: AlphaZero Accelerates Reinforcement Learning
Por um escritor misterioso
Descrição
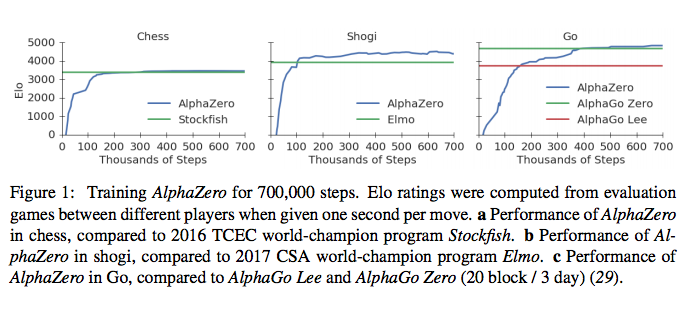
Google’s DeepMind has once again surprised the machine learning community, this time with the introduction of AlphaZero — a new algorithm that can quickly surpass human board game performance through reinforcement learning self-play. It was was just two months that DeepMind published their Nature paper on AlphaGo Zero, which mastered the game of Go in
MuZero, AlphaZero, and AlphaDev: Optimizing computer systems - Google DeepMind

Deepmind AlphaZero - Mastering Games Without Human Knowledge

Adaptive Warm-Start MCTS in AlphaZero-Like Deep Reinforcement Learning

A survey of deep reinforcement learning application in 5G and beyond network slicing and virtualization - ScienceDirect
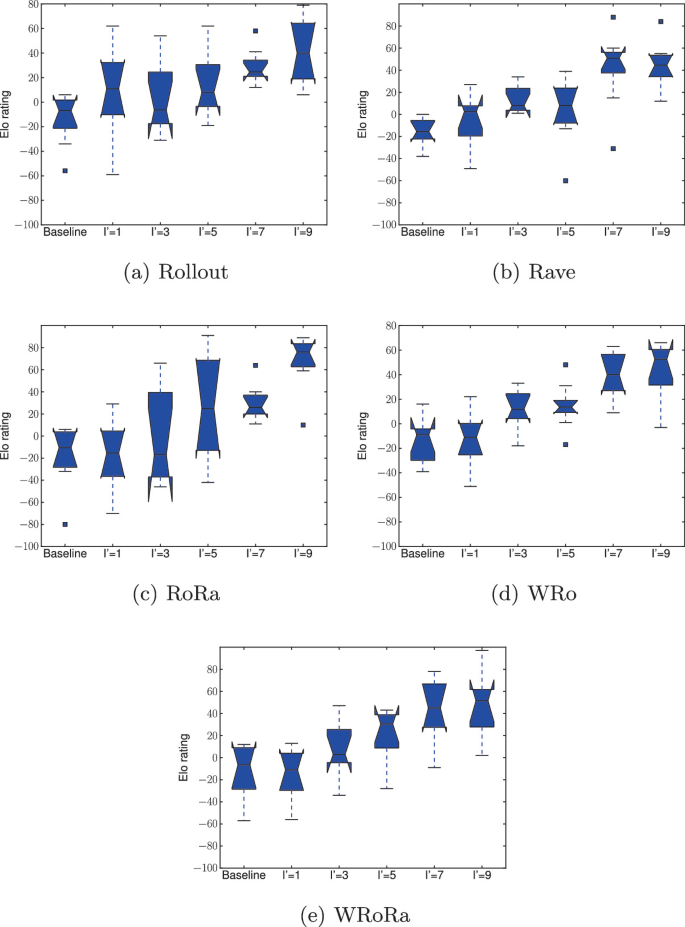
Adaptive Warm-Start MCTS in AlphaZero-Like Deep Reinforcement Learning

Frontiers AlphaZe∗∗: AlphaZero-like baselines for imperfect information games are surprisingly strong
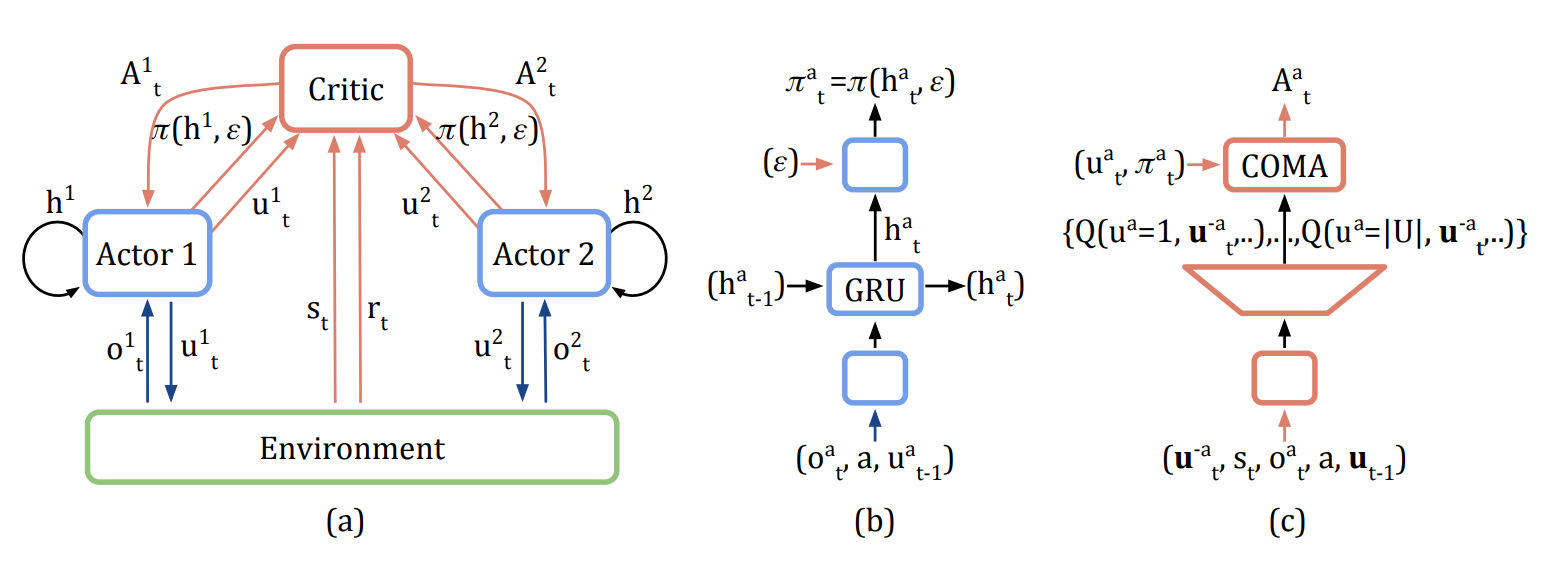
Reinforcement Learning Reading Group – Page 3 – Reinforcement Learning Reading Group for the Parr Group and Associates

David Silver: AlphaGo, AlphaZero, and Deep Reinforcement Learning
Self-play reinforcement learning in AlphaGo Zero. a The program plays a

A Journey to Reinforcement Learning
From Zero to Master in Hours: AlphaZero Accelerates Reinforcement Learning, by Synced, SyncedReview

PDF] Accelerating and Improving AlphaZero Using Population Based Training
de
por adulto (o preço varia de acordo com o tamanho do grupo)